Rust 程序内存布局
内存布局看似是底层和距离应用程序开发比较遥远的概念集合,但其对前端应用的功能实现颇具现实意义。从WASM业务模块至Nodejs N-API插件,无处不涉及到FFI跨语言互操作。甚至,做个文本数据的字符集转换也得FFI调用操作系统链接库libiconv,因为这意味着更小的.exe/.node发布文件。而C ABI与内存布局正是跨(计算机)语言数据结构的基础。
大约两个月前,在封装FFI闭包(不是函数指针)过程中,我重新梳理了Rust内存布局知识点。然后,就有冲动写这么一篇长文。今恰逢国庆八天长假,汇总我之所知与大家分享。开始正文...
一、存储宽度size与对齐位数alignment — 内存布局的核心参数
变量值在内存中的存储信息包含两个重要属性
- 首字节地址address
- 存储宽度size 而这两个值都不是在分配内存那一刻的“即兴选择”。而是,遵循着一组规则:
- address与size都必须是【对齐位数alignment】的自然数倍。比如说,
- 对齐位数alignment等于1字节的变量值可保存于任意内存地址address上。
- 对齐位数alignment等于2字节且有效数据长度等于3字节的变量值
- 仅能保存于偶数位的内存地址address上。
- 存储宽度size也得是4字节 — 从有效长度3字节到存储宽度4字节的扩容过程被称作“对齐”。
- 存储宽度size等于0字节的变量值可接受任意正整数作为其对齐位数alignment — 惯例是1字节。
- 对齐位数alignment必须是2的自然数次幂。即,
alignment = 2 ^ N且N是≼ 29的自然数。 - 存储宽度size是有效数据长度加对齐填充位数的总和字节数 — 这一点可能有点儿反直觉。
- address,size与alignment的计量单位都是“字节”。
正是因为address,size与alignment之间存在倍数关系,所以程序对内存空间的利用一定会出现冗余与浪费。这些被浪费掉的“边角料”则被称作【对齐填充alignment padding】。对齐填充的计量单位也是字节。根据“边角料”出现的位置不同,对齐填充alignment padding又分为:
- 小端填充(Little-Endian padding) — 0填充位出现在有效数据右侧的低位。
- 大端填充(Big-Endian padding) — 0填充位出现在有效数据左侧的高位。
文字抽象,图直观。一图抵千词,请看图
延伸理解:借助于对齐位数,物理上一维的线性内存被重构为了逻辑上N维的存储空间。不严谨地讲,一个数据类型 ➜ 对应一个对齐位数值 ➜ 按一个【单位一】将内存空间均分一遍 ➜ 形成一个仅存储该数据类型值(且只存在于算法与逻辑中)的维度空间。然后,在保存该数据类型的新值时,只要
- 选择进入正确的维度空间
- 跳过已被占用的【单位一】(这些【单位一】是在哪一个维度空间被占用、是被谁占用和怎么占用并不重要)
- 寻找连续出现且数量足够的【单位一】
就行了。
如果【对齐位数alignment】与【存储宽度size】在编译时已知,那么该类型<T: Sized>就是【静态分派】Fixed Sized Type。于是,
・类型的对齐位数可由 std::mem::align_of:: ・类型的存储宽度可由 std::mem::size_of:: 若【对齐位数alignment】与【存储宽度size】在运行时才可计算知晓,那么该类型<T: ?Sized>就是【动态分派】Dynamic Sized Type。于是, ・值的对齐位数可由 std::mem::align_of_val:: ・值的存储宽度可由 std::mem::size_of_val:: 若变量值的有效数据长度 否则,变量的【存储宽度size】就是既要大于等于【有效数据长度payload_size】,又是【对齐位数alignment】自然数倍的最小数值。 这个计算过程的伪码描述是: 这个计算被称作“(自然数倍)对齐”。 基本数据类型包括 瘦指针的内存布局与usize类型是一致的。因此,在不同设备和不同架构上,其性能表现略有不同 胖指针的存储宽度 存储宽度size是全部元素存储宽度之和 对齐位数alignment与单个元素的对齐位数一致。 存储宽度size = 0 Byte 对齐位数alignment = 1 Byte 所有零宽度数据类型都是这样的内存布局配置。 来自【标准库】的零宽度数据类型包括但不限于: 复合数据结构的内存布局描绘了该数据结构(紧内一层)字段的内存位置“摆放”关系(比如,间隙与次序等)。在层叠嵌套的数据结构中,内存布局都是就某一层数据结构而言的。它既承接不了来自外层父数据结构的内存布局,也决定不了更内层子数据结构的内存布局,更代表不了整个数据结构内存布局的总览。举个例子, 自定义数据结构的内存布局包含如下五个属性 自定义枚举类enum的内存布局一般与枚举类分辨因子discriminant的内存布局一致。更复杂的情况,请见下文章节。 编译器内置了四款内存布局方案,分别是 相较于C内存布局,Rust内存布局面向内存空间利用率做了优化 — 省内存。具体的技术手段包括Rust编译器 以C ABI中间格式为桥的C内存布局虽然实现了Rust跨语言数据结构,但它却更费内存。这主要出于两个方面原因: 以费内存为代价,C内存布局赋予Rust数据结构的另一个“超能力”就是:“仅通过变换【指针类型】就可将内存上的一段数据重新解读为另一个数据类型的值”。比如,void * / std::ffi::c_void被允许指向任意数据类型的变量值例程。但在Rust内存布局下,需要调用专门的标准库函数std::intrinsics::transmute()才能达到相同的目的。 除了上述鲜明的差别之外,C与Rust内存布局都允许【对齐位数alignment】参数被微调,而不一定总是全部字段alignment中的最大值。这包括但不限于: 结构体算是最“中规中矩”的数据结构。无论是否对结构体的字段重新排序,只要将它们一个不落地铺到内存上就完成一多半功能了。所以,结构体存储宽度struct.size是全部字段size之和再(自然数倍)对齐于【结构体对齐位数struct.alignment】的结果。有点抽象上伪码 相较于Rust内存布局优化算法的错综复杂,我好似只能讲清楚C内存布局的始末: 其次,声明一个(可修改的)游标变量 接着,沿着源码中字段的声明次序,逐一处理各个字段: 【对齐】若游标变量值 【定位】当前游标的位置就是该字段的首字节偏移量 跳过当前字段宽度field.size — 递归算法求值子数据结构的存储宽度。字段子数据结构的内存布局对上一层父数据结构是黑盒的。 继续处理下一个字段。 然后,在结构体内全部字段都被如上处理之后, 至此,结构体的C内存布局结束。然后, 形象地讲,联合体是给内存中同一段字节序列准备了多套“数据视图”,而每套“数据视图”都尝试将该段字节序列解释为不同数据类型的值。所以,无论在联合体内声明了几个字段,都仅有一个字段值会被保存于物理存储之上。从原则上讲,联合体union的内存布局一定与占用内存最多的字段一致,以确保任何字段值都能被容纳。从实践上讲,有一些细节处理需要斟酌: 举个例子,联合体Example0内包含了u8与u16类型的两个字段,那么Example0的内存布局就一定与u16的内存布局一致。再举个例子, 看答案之前,不防先心算一下,程序向标准输出打印的结果是多少。演算过程如下: 再来一个更复杂点儿的例子, 同样,在看答案之前,不防先心算一下,程序向标准输出打印的结果是多少。演算过程如下: 思维敏锐的读者可以已经注意到:单字段【结构体】与单字段【联合体】的内存布局是相同的,因为数据结构自身的内存布局就是唯一字段的内存布局。不信的话,执行下面的例程试试 突破“枚举”字面含义的束缚,Rust的创新使Rust enum与传统计算机语言中的同类项都不同。Rust枚举类 在Rust References一书中, 禁忌:C内存布局的枚举类必须至少包含一个枚举值。否则,编译器就会报怨: 因为“轻装”枚举值的唯一有效数据就是“记录了哪个枚举项被选中的”分辨因子discriminant,所以枚举类的内存布局就是枚举类【整数类型】分辨因子的内存布局。即, 别庆幸!故事远没有看起来这么简单,因为【整数类】是一组数字类型的总称(馁馁的“集合名词”)。所以,它包含但不限于 维系FFI两端Rust和C枚举类分辨因子都采用相同的整数类型才是最“坑”的,因为 C / Cpp enum实例可存储任意类型的整数值(比如,char,short,int和long)— 部分原因或许是C系语法灵活的定义形式:“typedef enum块 + 具名常量”。所以,C / Cpp enum非常适合被做成“比特开关”。但在Rust程序中,就不得不引入外部软件包bitflags了。 C内存布局Rust枚举类分辨因子discriminant只能是i32类型 — 【存储宽度size】是固定的4字节。 Rust内存布局·枚举类·分辨因子discriminant的整数类型是编译时由rustc决定的,但最宽支持到isize类型。 这就对FFI - C端的程序设计提出了额外的限制条件:至少,由ABI接口导出的枚举值得用int类型定义。否则,Rust端FFI函数调用就会触发U.B.。FFI门槛稍有上升。 扼要归纳: FFI - Rust端C内存布局的枚举类对FFI - C端枚举值的【整数类型】提出了“确定性假设invariant”:枚举值的整数类型是int且存储宽度等于4字节。 C端程序员必须硬编码所有枚举值的数据类型,以满足该假设。 FFI跨语言互操作才能成功“落地”,而不是发生U.B.。 来自C端的迁就固然令人心情愉悦,但新应用程序难免要对接兼容遗留系统与旧链接库。此时,再给FFI - C端提要求就不那么现实了 — 深度改动“屎山”代码风险巨大,甚至你可能都没有源码。**【数字类型·内存布局】**正是解决此棘手问题的技术方案: 以【元属性】 明确指示Rust编译器采用给定【整数类型】的内存布局,组织【分辨因子discriminant】的数据存储,而不总是遵循i32内存布局。 从C / Cpp整数类型至Rust内存布局元属性的映射关系包括但不限于 举个例子, 上面代码定义的是C内存布局的“轻装”枚举类Example5,因为它的每个枚举值不是“无字段”,就是“单位类型”。于是,Example5的内存布局就是i32类型的 再举个例子, 上面代码定义的是【数字类型·内存布局】的“轻装”枚举类Example6。它的内存布局是u8类型的 【“重装”枚举类】绝对是Rust语言设计的一大创新,但同时也给FFI跨语言互操作带来了严重挑战,因为在其它计算机语言中没有概念对等的核心语言元素“接得住它”。对此,在做C内存布局时,编译器rustc会将【“重装”枚举类】“降维”成一个双字段结构体: 前者记录选中项的“索引值” — 谁被选中;后者记忆选中项内的值:根据索引值,以对应的数据类型,读/写联合体实例的字段值。 文字描述着实有些晦涩与抽象。边看下图,边再体会。一图抵千词!(关键还是对union数据类型的理解) 上图中有三个很细节的知识点容易被读者略过,所以在这里特意强调一下: 举个例子, 看答案之前,不防先心算一下,程序向标准输出打印的结果是多少。演算过程如下: 哎!看见没,C内存布局还是比较费内存的,一少半都是空白“边角料”。 【“重装”枚举类】同样会遇到FFI - ABI两端【Rust枚举类分辨因子discriminant】与【C枚举值】整数类型一致约定的难点。为了迁就C端遗留系统和旧链接库对枚举值【整数类型】的选择,Rust编译器依旧选择“降维”处理enum。但,这次不是将enum变形成struct,而是跳过struct封装和直接以union为“话事人”。同时,将【分辨因子·枚举值】作为union字段子数据结构的首个字段: 文字描述着实有些晦涩与抽象。边看下图,边对比上图,边体会。一图抵千词! 由上图可见,C与【数字类型】的混合内存布局 举个例子,假设目标架构是32位系统, 看答案之前,不防先心算一下,程序向标准输出打印的结果是多少。演算过程如下: 哎!看见没,C 内存布局还是比较费内存的,一少半的“边角料”。 若不以C加【数字类型】的混合内存布局来组织枚举类enum Example9的数据存储,而仅保留【数字类型】内存布局,那么上例中被降维后的【联合体】与【结构体】就都会缺省采用Rust内存布局。参见下图: 补充于最后,思维活跃的读者这次千万别想太多了。没有 仅【枚举类】支持【数字类型·内存布局】。而且,将无枚举值的枚举类注释为【数字类型·内存布局】会导致编译失败。举个例子 会导致编译失败 “透明”不是指“没有”,而是意味着:在层叠嵌套数据结构中,外层数据结构的【对齐位数】与【存储宽度】等于(紧)内层数据结构的【对齐位数】和【存储宽度】。因此,它仅适用于 原则上,数据结构中的唯一字段必须是非零宽度的。但是,若【透明·内存布局】数据结构涉及到了 ,那么Rust内存布局的灵活性也允许:结构体和“重装”枚举值额外包含任意数量的零宽度字段。比如, 看答案之前,不防先心算一下,程序向标准输出打印的结果是多少。演算过程如下: 因为Example14.Variant0.1字段是零宽度数据类型PhantomData,所以它的 因为【透明·内存布局】,所以 外层枚举类的 不同于【数字类型·内存布局】,【透明·内存布局】不被允许与其它内存布局混合使用。比如, ・trait Object与由胖指针&dyn Trait/Box ・闭包Closure没有固定的【内存布局】。 只有Rust与C内存布局具备微调能力,且只能修改【对齐位数alignment】参数值。另外,不同数据结构可做的微调操作也略有不同: 数据结构【对齐位数alignment】值的增加与减少需要使用不同的元属性修饰符 align(x)与packed(x)修饰符的实参是【目标】字节数,而不是【增量】字节数。所以,#[repr(align(8))]指示编译器增加对齐数至8字节,而不是增加8字节。另外,新对齐位数必须是2的自然数次幂。 首先,枚举类不允许下调对齐位数。 其次,上调枚举类的对齐位数也会触发“内存布局重构”的负作用。编译器会效仿Newtypes 设计模式重构 由上图可见,在内存布局重构之后,C内存布局继续保留在枚举类上,而align(16)修饰符仅对外层的结构体有效。所以,从底层实现来讲,枚举类是不支持内存布局微调的,仅能借助外层的Newtypes数据结构间接限定。 以上面的数据结构为例, 看答案之前,不防先心算一下,程序向标准输出打印的结果是多少。演算过程如下: 内存布局是一个非常宏大技术主题,这篇文章仅是抛砖引玉,讲的粒度比较粗,涉及的具体数据结构也都很基础。更多FFI和内存布局的实践经验沉淀与知识点汇总,我将在相关技术线的后续文章中陆续分享。存储宽度size的对齐计算
payload_size正好是该变量类型【对齐位数alignment】的自然数倍,那么该变量的【存储宽度size】就是它的【有效数据长度payload_size】。即,size = payload_size;。variable.size = variable.payload_size.next_multiple_of(variable.alignment);
二、简单内存布局
基本数据类型
bool,u8,i8,u16,i16,u32,i32,u64,i64,u128,i128,usize,isize,f32,f64和char。它们的内存布局在不同型号的设备上略有差异。FST瘦指针
DST胖指针
size是usize类型的两倍,对齐位数却与usize相同。就依赖于设备/架构的性能表现而言,其与瘦指针行为一致:数组[T; N],切片[T]和str
str就是满足UTF-8编码规范的增强版[u8]切片。array.size = std::mem::size_of::<T>() * array.len();
array.alignment = std::mem::align_of::<T>();
()单位类型
std::marker::PhantomData<T> — 绕过“泛型类型形参必须被使用”的编译规则。进而,成就类型状态设计模式中的Phantom Type。std::marker::PhantomPinned<T> — 禁止变量值在内存中“被挪来挪去”。进而,成就异步编程中的“自引用结构体(self-referential struct)”。三、自定义数据结构的内存布局
#[repr(C)]
struct Data {
id: u32,
name: String
}
#[repr(C)]仅只代表最外层结构体Data的两个字段id和name是按C内存布局规格“摆放”在内存中的。但,#[repr(C)]并不意味着整个数据结构都是C内存布局的,更改变不了name字段的String类型是Rust内存布局的事实。若你的代码意图是定义完全C ABI的结构体,那么【原始指针】才是该用的类型。use ::std::ffi::{c_char, c_uint};
#[repr(C)]
struct Data {
id: c_uint,
name: *const c_char // 注意对比
}
内存布局核心参数
预置内存布局方案
#[repr(C)]#[repr(u8 / u16 / u32 / u64 / u128 / usize / i8 / i16 / i32 / i64 / i128 / isize)] #[repr(C, u8)]。#[repr(transparent)] 预置内存布局方案对比
#[repr(C, align(8))]将C内存布局中的【对齐位数】上调至8字节#[repr(packed)]将默认Rust内存布局中的【对齐位数】下调至1字节结构体struct的C内存布局
struct.size = struct.fields().map(|field| field.size).sum() // 第一步,求全部字段宽度值之和
.next_multiple_of(struct.alignment); // 第二步,求既大于等于【宽度值之和】,又是`struct.alignment`自然数倍的最小数值
首先,结构体自身的对齐位数struct.alignment就是全部字段对齐位数field.alignment中的最大值。struct.alignment = struct.fields().map(|field| field.alignment).max();
offset_cursor以实时跟踪(参照于结构体首字节地址的)字节偏移量。游标变量的初始值为0表示该游标与结构体的内存起始位置重合。let mut offset_cursor = 0;
offset_cursor不是当前字段对齐位数field.alignment的自然数倍(即,未对齐),就计算既大于等于offset_cursor又是field.alignment自然数倍的最小数值。并将计算结果更新入游标变量offset_cursor,以插入填充位对齐和向后推移字段在内存中的”摆放“位置。if offset_cursor.rem_euclid(field.alignment) > 0 {
offset_cursor = offset_cursor.next_multiple_of(field.alignment);
}
field.offset = offset_cursor;
offset_cursor += field.size
offset_cursor不是结构体对齐位数struct.alignment的自然数倍(即,未对齐),就计算既大于等于offset_cursor又是struct.alignment自然数倍的最小数值。并将计算结果更新入游标变量offset_cursor,以增补填充位对齐和扩容有效数据长度至结构体存储宽度。if offset_cursor.rem_euclid(struct.alignment) > 0 {
offset_cursor = offset_cursor.next_multiple_of(struct.alignment);
}
struct.size = offset_cursor;
std::alloc::GlobalAlloc就能够拿着这套“策划案”向操作系统申请内存空间去了。由此可见,每次【对齐】处理都会在有效数据周围“埋入”大量空白“边角料”(学名:对齐填充位alignment padding)。但出于历史原因,为了完成与其它计算机语言的FFI互操作,这些浪费还是必须的。下面附以完整的伪码辅助理解// 1. 结构体的【对齐位数】就是它的全部字段【对齐位数】中的最大值。
struct.alignment = struct.fields().map(|field| field.alignment).max();
// 2. 声明一个游标变量,以实时跟踪(相对于结构体首字节地址)的偏移量。
let mut offset_cursor = 0;
// 3. 按照字段在源代码中的词法声明次序,逐一遍历每个字段。
for field in struct.fields_in_declaration_order() {
if offset_cursor.rem_euclid(field.alignment) > 0 {
// 4. 需要【对齐】当前字段
offset_cursor = offset_cursor.next_multiple_of(field.alignment);
} // 5. 【定位】字段的偏移量就是游标变量的最新值。
field.offset = offset_cursor;
// 6. 在跳过当前字段宽度的字节长度(含对齐填充字节数)
offset_cursor += field.size;
}
if offset_cursor.rem_euclid(struct.alignment) > 0 {
// 7. 需要【对齐】结构体自身
offset_cursor = offset_cursor.next_multiple_of(struct.alignment);
}
// 8. 【定位】结构体的宽度(含对齐填充字节数)就是游标变量的最新值。
struct.size = offset_cursor;
联合体union的C内存布局
union.alignment等于全部字段对齐位数中的最大值(同结构体)。union.alignment = union.fields().map(|field| field.alignment).max();
union.size = union.fields().map(|field| field.size).max() // 第一步,求最长字段的宽度值
.next_multiple_of(union.alignment); // 第二步,求既大于等于【最长 字段宽度值】,又是`union.alignment`自然数倍的最小数值
use ::std::mem;
#[repr(C)]
union Example1 {
f1: u16,
f2: [u8; 4],
}
println!("alignment = {1}; size = {0}", mem::size_of::<Example1>(), mem::align_of::<Example1>())
use ::std::mem;
#[repr(C)]
union Example2 {
f1: u32,
f2: [u16; 3],
}
println!("alignment = {1}; size = {0}", mem::size_of::<Example2>(), mem::align_of::<Example2>())
不经意的巧合
use ::std::mem;
#[repr(C)]
struct Example3 {
f1: u16
}
#[repr(C)]
union Example4 {
f1: u16
}
// struct 内存布局 等同于 union 的内存布局
assert_eq!(mem::align_of::<Example3>(), mem::align_of::<Example4>());
assert_eq!(mem::size_of::<Example3>(), mem::size_of::<Example4>());
// struct 内存布局 等同于 u16 的内存布局
assert_eq!(mem::align_of::<Example3>(), mem::align_of::<u16>());
assert_eq!(mem::size_of::<Example3>(), mem::size_of::<u16>());
枚举类enum的C内存布局
error[E0084]: unsupported representation for zero-variant enum。“轻装”枚举类的内存布局
LightEnum.alignment = discriminant.alignment; // 对齐位数
LightEnum.size = discriminant.size; // 存储宽度
Rust C 存储宽度 u8 / i8 unsigned char / char 单字节 u16 / i16 unsigned short / short 双字节 u32 / i32 unsigned int / int 四字节 u64 / i64 unsigned long / long 八字节 usize / isize 没有概念对等项,可能得元编程了 等长于目标架构“瘦指针”宽度 #[repr(整数类型名)]注释枚举类定义C Rust 元属性 unsigned char / char #[repr(u8)] / #[repr(i8)] unsigned short / short #[repr(u16)] / #[repr(i16)] unsigned int / int #[repr(u32)] / #[repr(i32)] unsigned long / long #[repr(u64)] / #[repr(i64)] use ::std::mem;
#[repr(C)]
enum Example5 { // ”轻装“枚举类,因为
A(), // field-less variant
B {}, // field-less variant
C // unit variant
}
println!("alignment = {1}; size = {0}", mem::size_of::<Example5>(), mem::align_of::<Example5>());
alignment = size = 4 Byte。use ::std::mem;
#[repr(u8)]
enum Example6 { // ”轻装“枚举类,因为
A(), // field-less variant
B {}, // field-less variant
C // unit variant
}
println!("alignment = {1}; size = {0}", mem::size_of::<Example6>(), mem::align_of::<Example6>());
alignment = size = 1 Byte。“重装”枚举类的内存布局
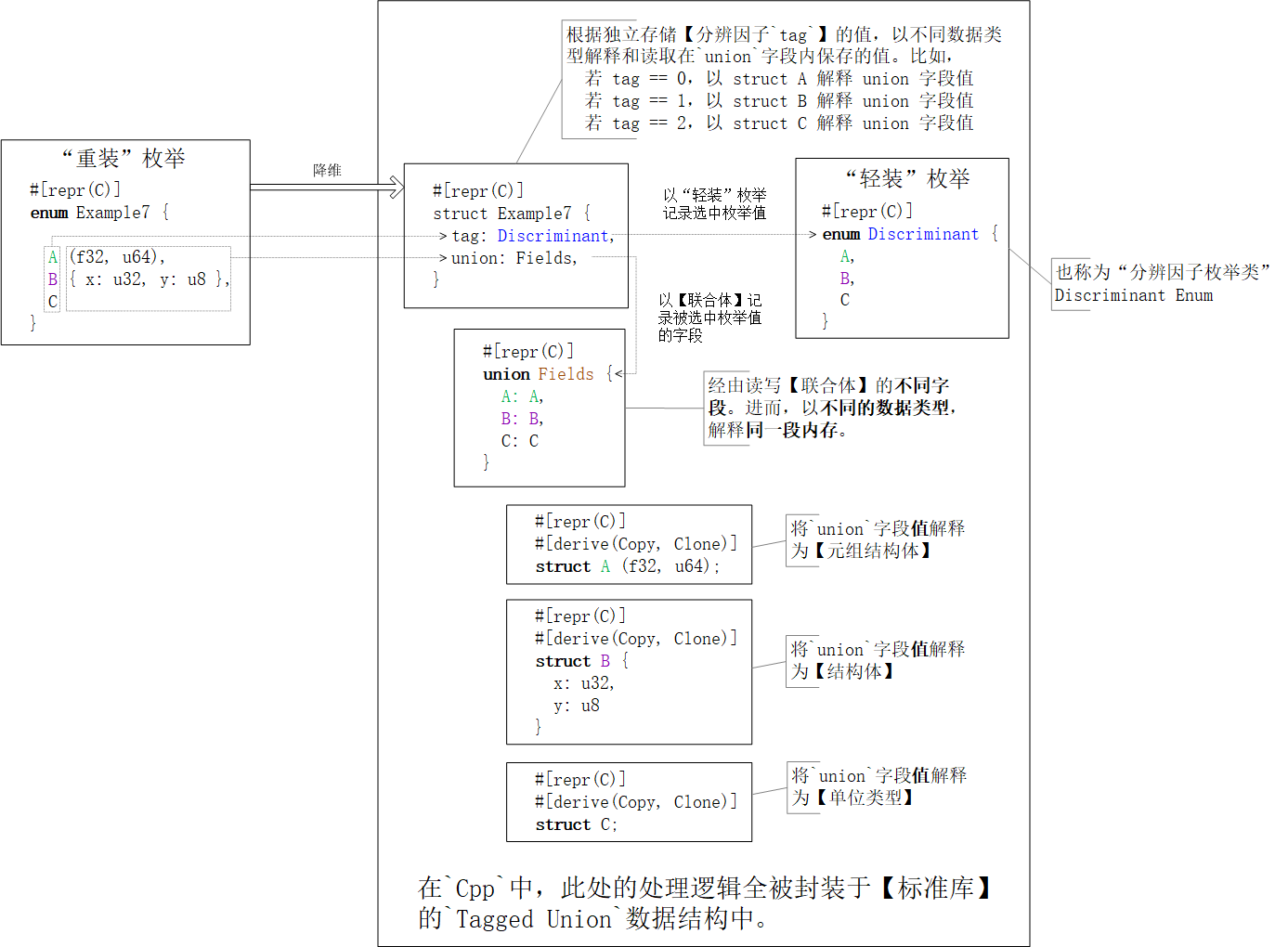
use ::std::mem;
#[repr(C)]
enum Example8 {
Variant0(u8),
Variant1,
}
println!("alignment = {1}; size = {0}", mem::size_of::<Example8>(), mem::align_of::<Example8>())
union.Variant0.alignment = union.Variant0.size = 1 Byteunion.Variant1.alignment = 1 Byte和union.Variant1.size = 0 Bytestruct.size ≈ 5 Byte (约等)struct.size = 8 Byte (直等)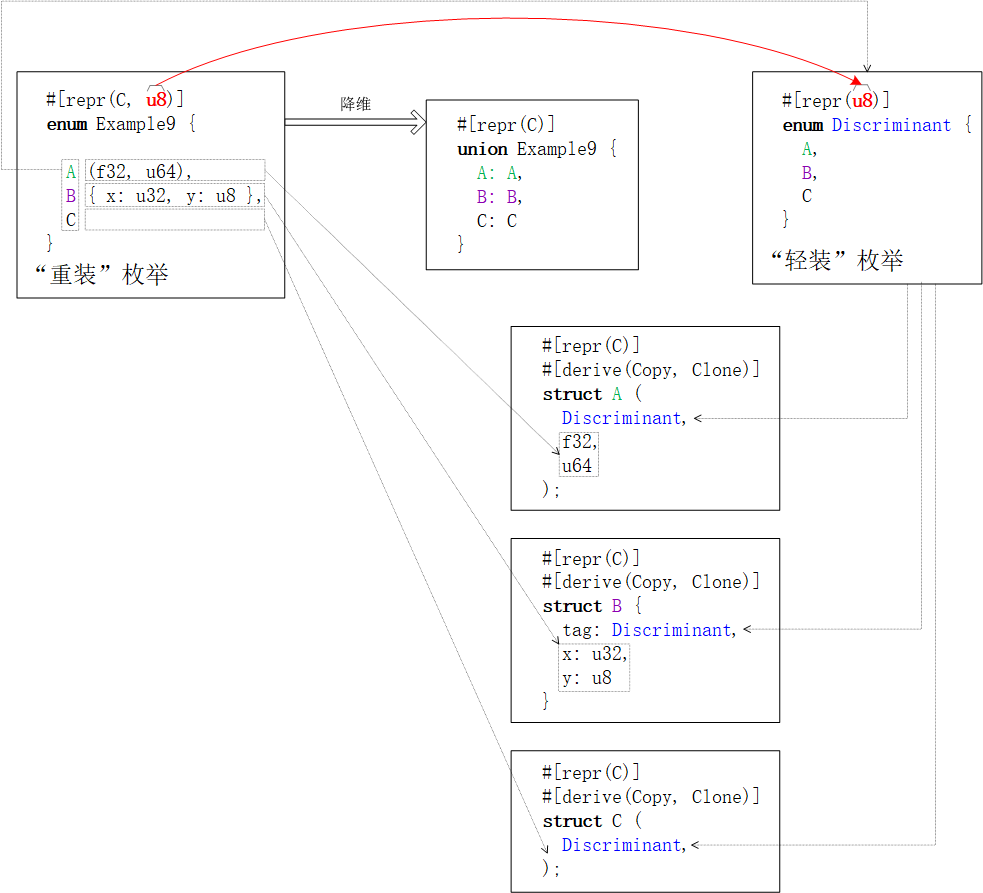
use ::std::mem;
#[repr(C, u16)]
enum Example10 {
Variant0(u8),
Variant1,
}
println!("alignment = {1}; size = {0}", mem::size_of::<Example10>(), mem::align_of::<Example10>())
Variant0.0.alignment = Variant0.0.size = 2 ByteVariant0.1.alignment = Variant0.1.size = 1 Byteunion.Variant0.alignment = 2 Byteunion.Variant1.alignment = union.Variant1.size = 2 Byteunion.alignment = 2 Byteunion.Variant0是双字段元组结构体。所以,struct的size是全部字段size之和。 Variant0.0.size = 2 ByteVariant0.1.size = 1 byteunion.Variant0.size ≈ 3 Byte(约等)union.Variant0.size = 4 Byte (直等)union.Variant1.size = 2 Byteunion.size = 4 Byte新设计方案好智慧
仅【数字类型·内存布局】的“重装”枚举类

#[repr(transparent, u16)]的内存布局组合,因为【透明·内存布局】向来都是“孤来孤往”的。数字类型·内存布局
#[repr(u16)]
enum Example12 {
// 没有任何枚举值
}
error[E0084]: unsupported representation for zero-variant enum。透明·内存布局
struct.alignment = struct.field.alignment;
struct.size = struct.field.size;
HeavyEnum.alignment = HeavyEnum::variant.field.alignment;
HeavyEnum.size = HeavyEnum::variant.field.size;
LightEnum.alignment = 1;
LightEnum.size = 0;
std::marker::PhantomData<T> 为类型状态设计模式,提供Phantom Type支持。std::marker::PhantomPinned<T> 为自引用数据结构,提供!Unpin支持。 举个例子,use ::std::{marker::PhantomData, mem};
#[repr(transparent)]
enum Example13<T> { // 含`Phantom Type`的“重装”枚举类
Variant0 (
f32, // 普通有数据字段
PhantomData<T> // 零宽度字段。泛型类型形参未落实到有效数据上。
)
}
println!("alignment = {1}; size = {0}", mem::size_of::<Example13<String>>(), mem::align_of::<Example13<String>>())
#[repr(C, u16)]是合法的#[repr(C, transparent)]和#[repr(transparent, u16)]就会导致语编译失败其它类型的内存布局
微调内存布局
#[repr(align(新·对齐位数))] 增加对齐位数至新值。将小于等于数据结构原本对齐位数的值输入align(x)修饰符是无效的。#[repr(packed(新·对齐位数))] 减少对齐位数至新值。将大于等于数据结构原本对齐位数的值输入packed(x)修饰符也是无效的。禁忌
align(x)与packed(x)修饰符不能共同注释一个数据类型定义。#[repr(packed(x))]数据结构不允许嵌套包含#[repr(align(y))]子数据结构。枚举类内存布局的微调
#[repr(align(x))] enum枚举类为嵌套包含了enum的#[repr(align(x))] struct元组结构体。一图抵千词,请参阅下图。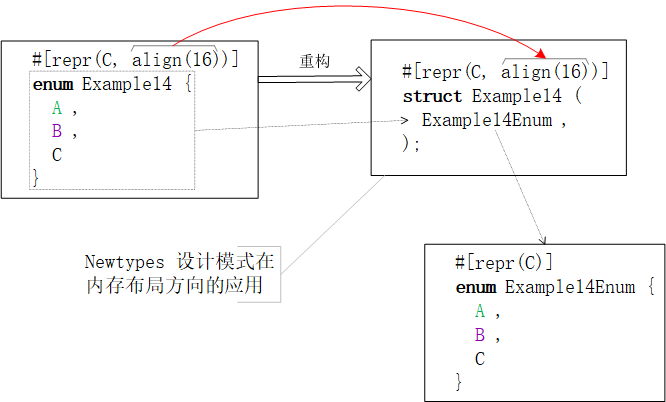
use ::std::mem;
#[repr(C, align(16))]
enum Example15 {
A,
B,
C
}
println!("alignment = {1}; size = {0}", mem::size_of::<Example15>(), mem::align_of::<Example15>())
size = 4 Byte。alignment = size = 4 Byte提升到alignment = size = 16 Byte。四、结束语